Kafka Connect: 同步 MySQL 的表到 Kafka
核心流程
Kafka Connect 是一个连接器,将数据搬到 Kafka,然后再存储到另一个地方,解耦了数据源和目标存储。
既然要把数据搬到 Kafka,所以需要提前准备好 Kafka 实例。
前置条件
- Kafka (本文示例版本:2.2.1-cdh6.3.1)
1. 启动 Kafka connect distributed
Kafka connect 就在 Kafka 安装包中,下载对应的安装包open in new window,本文下载 2.2.1 版本的 Kafka 安装包。
Kafka 支持单机和分布式部署,这里演示分布式部署。
下载解压后,首先修改配置,指定 Kafka 实例地址。
# cd /data/bigdata/kafka/kafka_2.12-2.2.1/
# vim config/connect-distributed.properties
# A list of host/port pairs to use for establishing the initial connection to the Kafka cluster.
bootstrap.servers=10.0.0.29:9092
# unique name for the cluster, used in forming the Connect cluster group. Note that this must not conflict with consumer group IDs
group.id=connect-cluster
2
3
4
5
6
另外几个参数(config.storage.topic, offset.storage.topic, status.storage.topic)使用默认即可。
启动之。
bin/connect-distributed.sh config/connect-distributed.properties
查看集群的配置。
8083 是 REST API 默认监听端口。
# curl localhost:8083
{"version":"2.2.1","commit":"55783d3133a5a49a","kafka_cluster_id":"thmuyps7QaeG9JbOXxnJsw"}
2
2. 安装 connector-plugins
默认配置只能看到这 2 个
# curl -s localhost:8083/connector-plugins | python -m json.tool
[
{
"class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"type": "sink",
"version": "2.2.1"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"type": "source",
"version": "2.2.1"
}
]
2
3
4
5
6
7
8
9
10
11
12
13
2.1 下载 JDBC Connector (Source and Sink)
下载 Download installationopen in new window
解压放到 kafka 的 plugins 目录下
2.2 下载 mysql-connector-java
Connect/J JDBC driver for MySQLopen in new window
放到 kafka 的 libs 目录下。
修改配置文件 config/connect-distributed.properties 中 connect 的插件地址
# Set to a list of filesystem paths separated by commas (,) to enable class loading isolation for plugins
# (connectors, converters, transformations). The list should consist of top level directories that include
# any combination of:
# a) directories immediately containing jars with plugins and their dependencies
# b) uber-jars with plugins and their dependencies
# c) directories immediately containing the package directory structure of classes of plugins and their dependencies
# Examples:
# plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors,
plugin.path=/data/bigdata/kafka/kafka_2.12-2.2.1/libs,/data/bigdata/kafka/kafka_2.12-2.2.1/plugins
2
3
4
5
6
7
8
9
重新启动后,可以看到有这些 connector-plugins
# curl -s localhost:8083/connector-plugins | python -m json.tool
[
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirAvroSourceConnector",
"type": "source",
"version": "0.0.0.0"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirBinaryFileSourceConnector",
"type": "source",
"version": "0.0.0.0"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirCsvSourceConnector",
"type": "source",
"version": "0.0.0.0"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirJsonSourceConnector",
"type": "source",
"version": "0.0.0.0"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirLineDelimitedSourceConnector",
"type": "source",
"version": "0.0.0.0"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirSchemaLessJsonSourceConnector",
"type": "source",
"version": "0.0.0.0"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.elf.SpoolDirELFSourceConnector",
"type": "source",
"version": "0.0.0.0"
},
{
"class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"type": "sink",
"version": "10.1.1"
},
{
"class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"type": "source",
"version": "10.1.1"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"type": "sink",
"version": "2.2.1"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"type": "source",
"version": "2.2.1"
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
3. 新增 mysql source connector
参照 connect-mysql-source.propertiesopen in new window,组装如下 JSON ,并注册 connector。
echo '{
"name":"mysql_source_hue_queryhistory",
"config":{
"connector.class":"JdbcSourceConnector",
"connection.url":"jdbc:mysql://10.0.0.15:3306/hue?user=hue&password=xxxxx",
"mode":"incrementing",
"table.whitelist":"desktop_document2",
"incrementing.column.name":"id",
"topic.prefix":"hue-"
}
}' | curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"
2
3
4
5
6
7
8
9
10
11
"connection.url":"jdbc:mysql://10.0.0.15:3306/hue?user=hue&password=xxxxx", MySQL的连接串,以 Hue 的查询记录为例 "mode":"incrementing" , 增量拉取MySQL表的数据 "incrementing.column.name":"id", 增量字段 "table.whitelist":"desktop_document2", 只拉某张表 "topic.prefix":"hue-" , 存储到 Kafka 中 topic 的命名规则
查看当前的 connector 列表 和 详情。
# curl localhost:8083/connectors
["mysql_source_hue_queryhistory"]
# curl -s localhost:8083/connectors/mysql_source_hue_queryhistory/config | python -m json.tool
{
"connection.url": "jdbc:mysql://10.0.0.15:3306/hue?user=hue&password=xxxxx",
"connector.class": "JdbcSourceConnector",
"incrementing.column.name": "id",
"mode": "incrementing",
"name": "mysql_source_hue_queryhistory",
"table.whitelist": "desktop_document2",
"topic.prefix": "hue-"
}
2
3
4
5
6
7
8
9
10
11
12
13
验证 Kafka 中对应 Topic 的数据
# bin/kafka-console-consumer.sh --bootstrap-server 10.0.0.29:9092 --topic hue-desktop_document2
在 Kafka 中也可看到对应 Topic 的生产情况
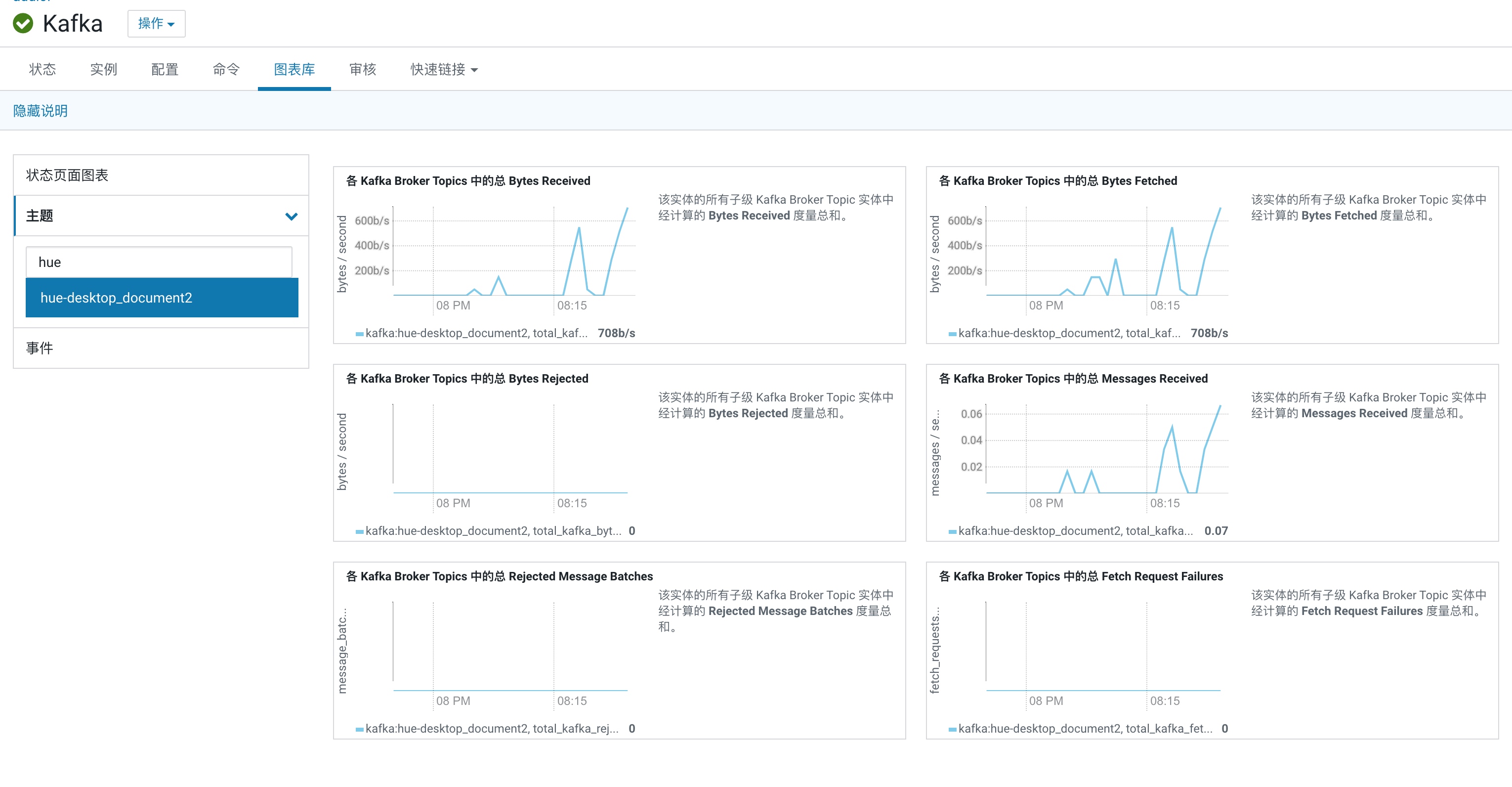
4. 扩展一下
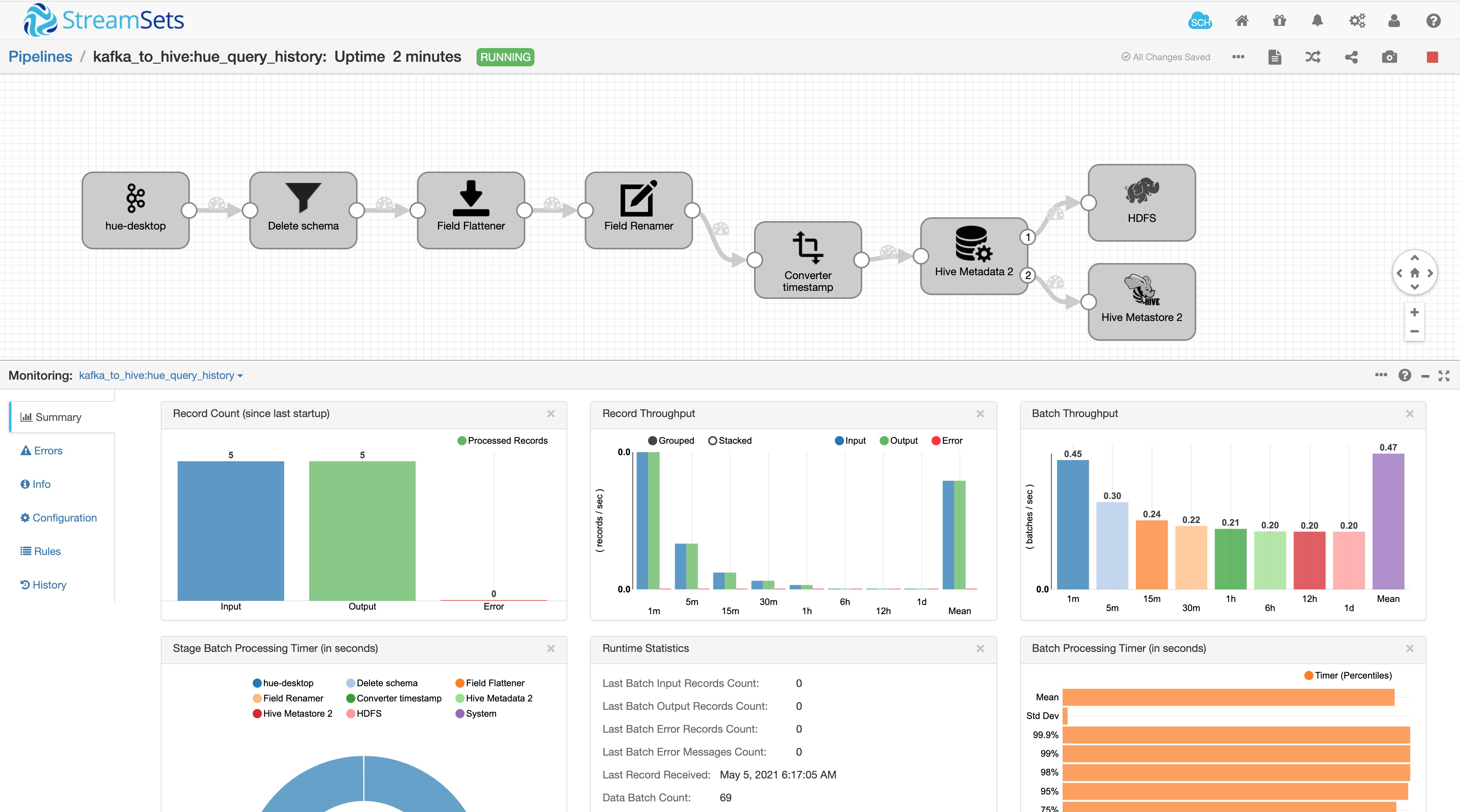
将 Kafka 中的数据搬到 Hive 中
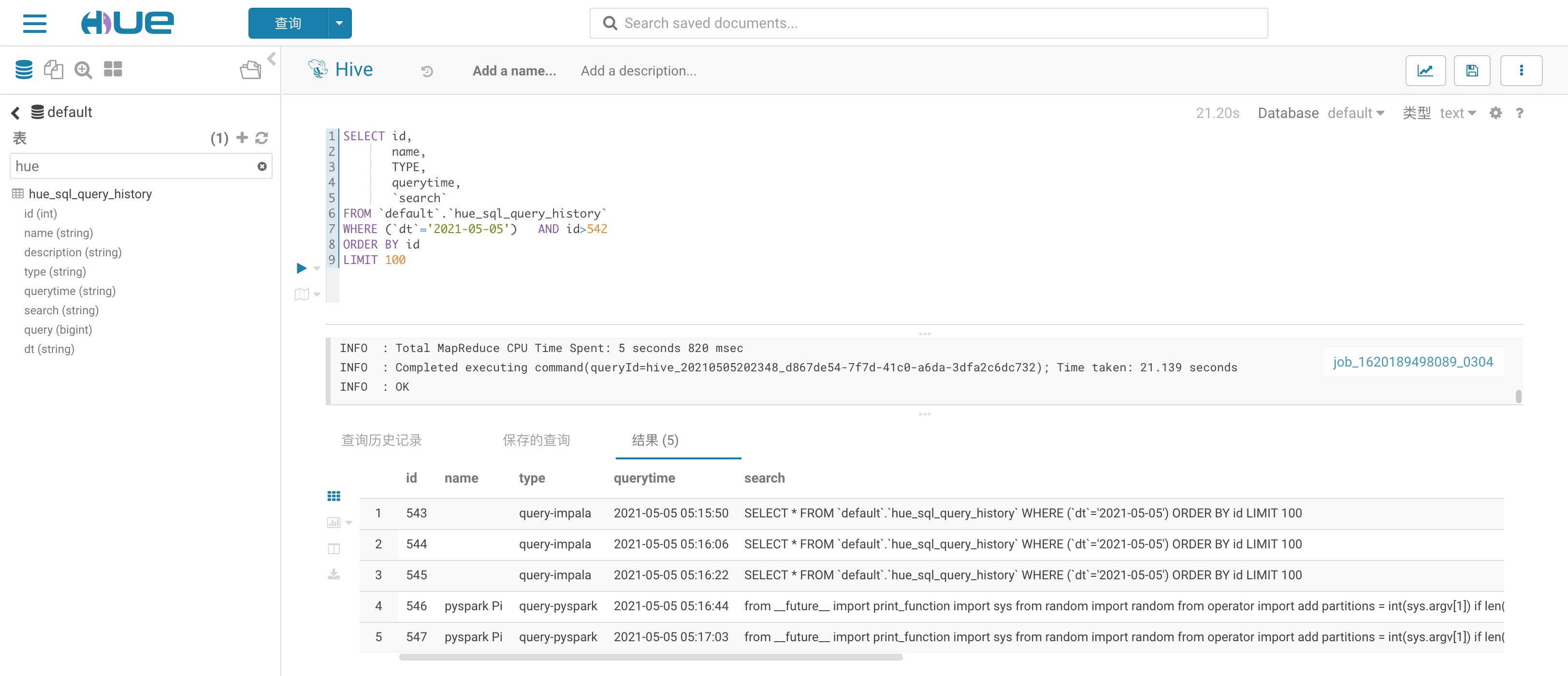
在 Hue 中查询
reference
- [1] Kafka. Kafka Connectopen in new window
- [2] Kafka. REST APIopen in new window